Business-critical applications may have different backup and recovery requirements to servers that don’t change often or store data. For applications that need to be recovered quickly, or that need to be backed up every few minutes or hours, Recovery Services values also provide a tool called Azure Site Recovery. Both Azure Backup and Azure Site Recovery are set up and managed by an Azure Recovery Services vault.
Whereas Azure Backup takes a one-off backup at daily intervals, Azure Site Recovery continually replicates your VM’s disks to another region. In the event that you need to failover, a new VM is created and attached to the replicated disk in the paired region, as we can see in the following diagram:
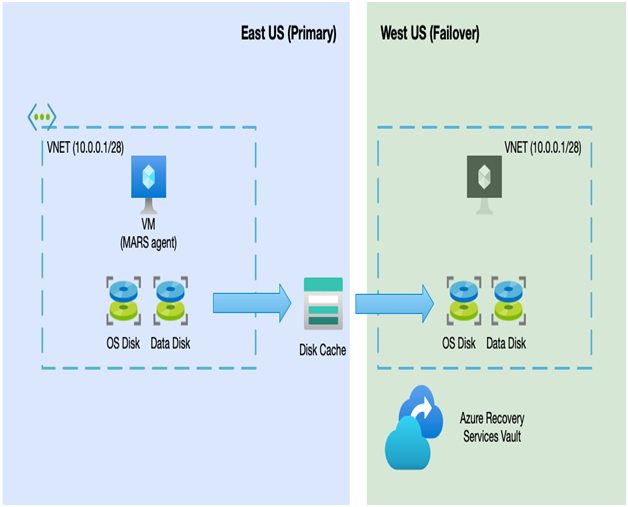
Figure 16.2 – Azure Site Recovery architecture
As we can see from the preceding diagram, Azure Site Recovery requires a VNET and subnet in the paired region that your replicated VMs can attach to. When you set up a VM to use Site Recovery, the setup wizard can either create the VNET and subnet for you or use an existing VNET you have already set up in the paired region.
Important Note
You must set up an Azure Recovery Services vault in the paired region that you wish to protect. For example, if the workload you wish to protect is in East US, you must create the vault in West US. This is because the replicated VM needs to exist in the paired region.
An important consideration of the network is how you will define your IP ranges. By default, the internal IP ranges that the paired VNET uses are the same as the primary region. If your VMs fail over, they therefore retain their original internal IP address.
If your VMs only use the internal IPs for communicating with each other, this will not cause an issue; however, if you connect to your VMs from an on-premises network over a VPN, you need to consider whether using a separate range and separate VPN to the paired region is required.
Public IP addresses cannot move as part of a failover process. If your VMs are accessed via public IPs, those IPs will change in the event of a failover. To overcome this issue, consider using a service such as Azure Traffic Manager to control connectivity to your services. We looked at using Azure Traffic Manager in Chapter 8, Network Connectivity and Security.
The replication process of Site Recovery ensures the lowest possible RTO. Because data is constantly being replicated to another region, when a failover occurs, the data is already where you need it – that is, you don’t need to wait for a restore to happen.
Azure Site Recovery works by creating snapshots of your VM and then replicating that data into the Recovery Services vault. To support the lowest possible RPO, Site Recovery takes two different types of snapshots when replicating your VM:
- Crash-consistent: Taken every 5 minutes. Represents all the data on the disk at that moment in time
- App-consistent: Crash consistent snapshots of the disks, plus an in-memory snapshot of the VM every 60 minutes
When you create your first Recovery Services vault and enable replication on a VM, a replication policy is created. The replication policy allows you to define how long crash-consistent snapshots, known as recovery points, are kept. The options are between 0 (none) and 72 hours.
The policy also allows you to modify the default crash-consistent snapshot from the default 1 hour to up to 12 hours.
Site Recovery also supports on-premises VMs as well as VMs in Azure. This provides you with a full DR site in Azure to protect against your own data center suffering an outage.
Site Recovery is the actual underlying mechanism used by Azure Migrate, which we covered in Chapter 10, Migrating Workloads to Azure.
Site Recovery can perform a failover automatically for you if your primary region goes offline, or you can manually failover services. Finally, you can also run DR drills, which will fully test a failover without disrupting your running workload.
With either drills or full DR failovers, you can group your VMs into workload groups called recovery plans.

Leave a Reply