Azure Repos allows you to control and manage code changes by enforcing versioning and tracking of changes across files. Code is stored in a repository and repositories use branches to provide an additional layer of management.
Each repository has at least one branch; by default, this is called the master branch. When a user wishes to work on the code within a branch, they clone that branch to their local computer and perform any changes they need. When changes are saved to the user’s computer, they do not automatically reflect in the repository. Instead, the developer must commit those changes to the local copy on their computer. Finally, changes are pushed to the remote repo so that others can see them.
For a single developer, this helps you track all your changes as each amendment you make is tracked and can be compared against previous versions. So, you can also revert commits to older versions should you need to.
When multiple developers are working on the same code base, there is the potential for the same files to be updated. Therefore, the process is to first perform a pull of the remote repo where you pull down any changes before you issue your own push. When you perform a pull, if conflicts are detected between the remote code and yours, you will be prompted to perform a merge. The merge process can be automatic, manual, or a combination of the two depending on the client software you are using and the conflicts themselves.
Once a merge has been completed and any conflicts resolved, the updated code can then be pushed back to the remote repository so that other developers can then pull down your code.
Although all work could be performed on the default master branch, it is better to create new branches for each piece of work or sprint. Creating a new branch makes a copy of the source branch that is independent. One possible usage scenario for this way of working is to create a new branch for each new iteration or feature that is being worked on. Once all work is completed, verified, and tested, the branch can then be merged back with the source. In this way, you always keep a working clean copy of your code.
Important Note
In agile, a sprint is a timeboxed period during which work will be performed. The amount of time is the same for every sprint within a project, and each sprint should finish with the deployment of working code. In this way, solutions involve multiple smaller releases over the project as opposed to one final release at the end of the project.
Another extension to this way of working is for each individual developer to create their own branch for the piece of work they are performing and enforce the use of a pull request.
A pull request is used instead of performing a merge with the source branch and is used to ensure that another developer reviews your code before allowing it to be merged. This is a great way of ensuring quality in your code as it means a second person must validate your changes and potentially prevent any issues.
Azure DevOps provides a series of options to control what users can do to a branch. For example, the master branch can be locked to only allow specific users to commit to it. Developers then work on their own branches and perform a pull request. Again, specific people such as senior developers can be set as the approvers of a pull request, and once approved, the merge into the master branch takes place. In this way, we can protect the master branch and enforce the use of code reviews.
The following diagram shows how this end-to-end process flow can work:
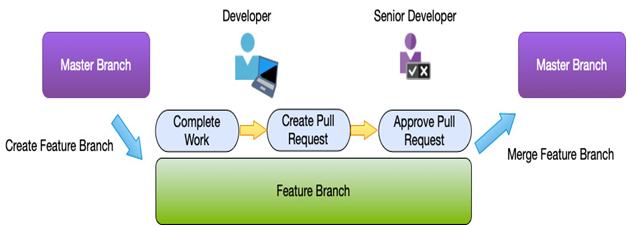
Figure 17.4 – DevOps branching process flow
With Azure Repos, you have a central storage repository for your ARM templates and scripts that tracks all your changes and provides tools for multiple DevOps engineers to work on them at the same time.
The next step of the process, once code has been built, is to build components with that code, which is where Azure Pipelines then helps.

Leave a Reply